51单片机 蓝牙/WiFi无线遥控智能家居系统设计 仿真 实物 串口 音乐 蓝牙 继电器 PWM 温度
本文共 2921 字,大约阅读时间需要 9 分钟。
51单片机
蓝牙/WiFi无线遥控智能家居系统设计
修改PWM占空比,占空比越高小灯越亮;占空比越低小灯越暗.

使用无源蜂鸣器播放天空之城音乐.
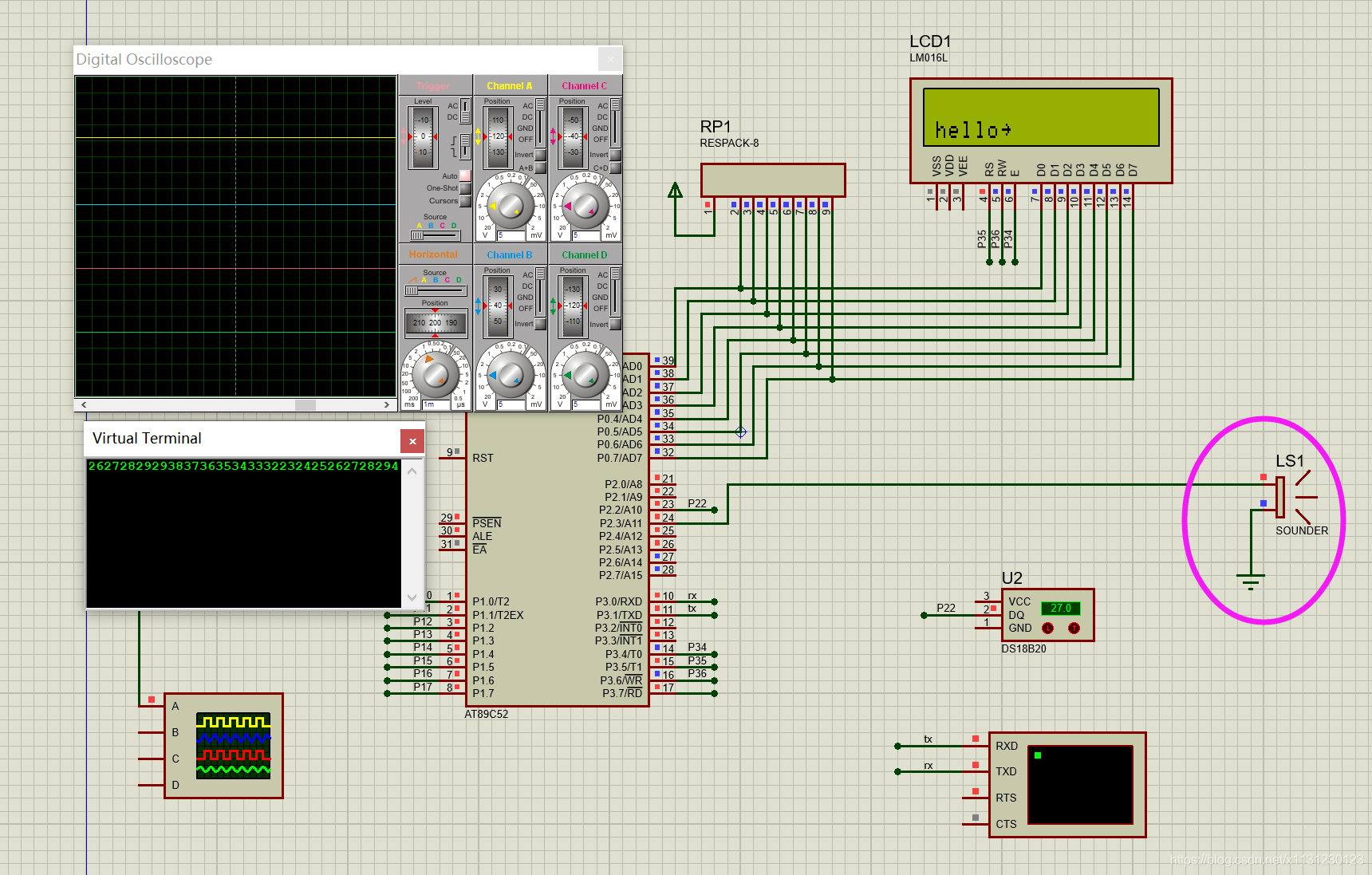
显示出ds18b20的温度.
 部分代码:
部分代码: void main(){ LCD_init();//初始化 LCD_write_str( 0, 1, "hello~" ); SerInit(); Print_Str("test");//测试用 DULA=1; P0=0X00; DULA=0; WELA=1; P0=0X00; WELA=0; while ( 1 ) { if ( mode == 1 ) { u = 0; /* 从第1个音符f[0]开始播放 */ while ( music0[u] != 0xff ) /* 只要没有读到结束标志就继续播放 */ { C = 460830 / music0[u]; TH0 = (8192 - C) / 32; /* 可证明这是13位计数器TH0高8位的赋初值方法 5 */ TL0 = (8192 - C) % 32; /* 可证明这是13位计数器TL0低5位的赋初值方法 */ TR0 = 1; /* 启动定时器T0 */ for ( t = 0; t < music0_JP[u]; t++ ) /* 控制节拍数 */ delay1(); /* 延时1个节拍单位 */ TR0 = 0; /* 关闭定时器T1 */ u++; /* 播放下一个音符 */ } TR0 = 0; /* 关闭定时器 */ sound = 1; /* 关闭蜂鸣器 */ }else if ( mode == 2 ) { temp = getTmpValue(); DisplayTEMP( temp ); sound = 1; delayMs(10); } }}void Uart_isr() interrupt 4 /* 中断接收程序 */{ if ( RI ) /* 判断是否接收完,接收完成后,由硬件置RI位 */ { Txd_data = SBUF; /* 读入缓冲区 */ RI = 0; /* 清标志 */ SBUF = Txd_data; while ( !TI ) ; /* 等待发送结束 */ TI = 0; /* 清除结束标志,以便再发送数据 */ if ( Txd_data == '1' ) { WELA=1; P0=0X00; WELA=0; mode = 0; init_timer0_pwm(); }else if ( Txd_data == '2' ) { if ( ZHANKONGBI < 9 ) ZHANKONGBI++; SBUF = '0' + ZHANKONGBI; while ( !TI ) ; /* 等待发送结束 */ TI = 0; /* 清除结束标志,以便再发送数据 */ }else if ( Txd_data == '3' ) { if ( ZHANKONGBI > 0 ) ZHANKONGBI--; SBUF = '0' + ZHANKONGBI; while ( !TI ) ; /* 等待发送结束 */ TI = 0; /* 清除结束标志,以便再发送数据 */ }else if ( Txd_data == '4' ) { init_timer0_yinyue(); mode = 1; WELA=1; P0=0X00; WELA=0; }else if ( Txd_data == '5' ) { mode = 5; WELA = 1; /* 改变电压之前先拉高 */ D6RL = 1; WELA = 0; /* 改变完了就拉低锁存 */ }else if ( Txd_data == '6' ) { mode = 5; WELA = 1; /* 改变电压之前先拉高 */ D6RL = 0; WELA = 0; /* 改变完了就拉低锁存 */ }else if ( Txd_data == '7' ) { mode = 2; WELA=1; P0=0X00; WELA=0; } }}sbit LED = P1 ^ 0;/* ==================定时器1中断服务程序=============== */void timer0_server( void )interrupt 1{ /* mode=0 pwm */ if ( mode == 0 ) { TH0 = (65536 - 1000) / 256; TL0 = (65536 - 1000) % 256; pwm_count++; if ( pwm_count == 10 ) { pwm_count = 0; LED = 0; } if ( ZHANKONGBI == pwm_count ) { LED = 1; } }else if ( mode == 1 ) { /* mode=1 yinyue */ sound = !sound; /* 将P3.7引脚输出电平取反,形成方波 */ TH0 = (8192 - C) / 32; /* 可证明这是13位计数器TH0高8位的赋初值方法 */ TL0 = (8192 - C) % 32; /* 可证明这是13位计数器TL0低5位的赋初值方法 */ }} 转载地址:http://nuce.baihongyu.com/
你可能感兴趣的文章